はじめに
Spark を Hadoop の基盤で動かしてみて、そもそもどういう仕組みで動いているんだろうか、と気になったので調べたことのメモ。
Spark のクラスターモード
Spark 自体に、クラスターモードという機能があるようで、ジョブ送信時にどのクラスターに接続するか、というのを指定できる。 これによって、分散システム基盤とうまく連動して処理が可能となっているようである。
2022 年 5 月時点の 3.2 系では、以下の4つが利用可能な模様。*1
- Standalone
- Apache Mesos (非推奨)
- Hadoop YARN
- Kubernetes
2.2.0 から K8s も実験的にサポートが開始され、2.3.0 で公式サポートという形になったようで、また、Mesos は非推奨となっている。
Spark のクラスターモードの構成
厳密には Spark の機能というよりは、外部リソースとして扱うための仕組み、というイメージになるのかもしれない。
spark-submit でアプリケーションを実行する際に、 --master オプションを利用することでどのクラスターモードを利用するかを指定できる。*2
YARN を利用する場合は --master yarn と指定する。*3
この場合、Cluster Manager に相当するのは YARN の Resource Manager になる。
Driver
main() 関数を実行し、SparkContext を作成するプロセス。
Executor
ワーカーノード上のアプリケーション用に起動されたプロセス。 タスクを実行し、タスク全体のメモリまたはストレージにデータを保持する。 Executor の中での処理はJob, Stage, Taskという段階的な処理になっているようだがこの辺りはまだ詳しくわかっていない。 *4
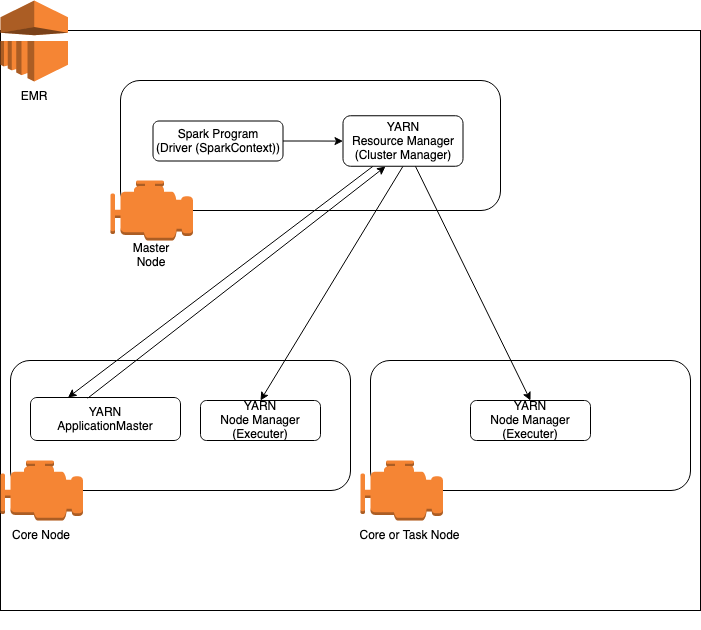
EMR で動く場合のイメージ図
まとめ
ざっと概要についてまとめた。 RDD とかはまだあまりわかっていないので追って雑にまとめたい。
*1:Cluster Mode Overview - Spark 3.2.0 Documentation
*2:Submitting Applications - Spark 3.2.0 Documentation
*3:Cluster Mode Overview - Spark 3.2.0 Documentation
*4:https://qiita.com/sigmalist/items/ea4127332abc12a99a45#spark%E3%81%AE%E5%87%A6%E7%90%86%E3%82%B8%E3%83%A7%E3%83%96%E3%82%B9%E3%83%86%E3%83%BC%E3%82%B8%E3%82%BF%E3%82%B9%E3%82%AF%E3%81%A8%E3%83%87%E3%83%BC%E3%82%BFrdd%E3%83%91%E3%83%BC%E3%83%86%E3%82%A3%E3%82%B7%E3%83%A7%E3%83%B3